

Table Of Contents:
The rise of multimodal AI and its impact on technology
What are multimodal AI models and why are they important?
How does multimodal AI work?
The challenges of managing multimodal data for AI models
Applications of multimodal AI in business
Why multimodal AI is important for the future
How TileDB helps develop multimodal AI
Frequently asked questions
Multimodal AI models are becoming the foundation of today’s most advanced AI systems, with the multimodal AI market predicted to surpass $20.5 billion by 2032. Rather than relying on a single type of input, these AI models combine multiple data modalities like text, images, video, audio, and high-dimensional scientific data like genomics and single-cell profiles to perform deeper analysis of complex real-world systems. By learning across modalities, multimodal models can capture context, relationships, patterns, and other insights that would be invisible in isolation, enabling more accurate predictions and effective decision-making.
Under the hood, multimodal AI’s transformative power comes from its ability to integrate and align diverse data sources at scale. But for many teams, managing multimodal data introduces significant challenges including fragmented storage, complex data integration workflows, performance bottlenecks, and growing operational overhead. Despite these hurdles, multimodal AI is already reshaping industries ranging from biomedical research and precision medicine to autonomous systems, geospatial intelligence, and enterprise analytics. So if 2025 revealed the versatility of multimodal AI inputs beyond text, 2026 promises to better integrate and analyze complex multimodal data in exciting applications like patient 360, geospatial analysis, and LIDAR technology.
In this article, we explore how multimodal AI models work, the systems-level challenges that limit their adoption, and why a unified data layer is critical for bringing disparate modalities together into a single, scalable platform that enables true omnimodal intelligence.
The rise of multimodal AI and its impact on technology
Multimodal AI has empowered machine learning systems that were once limited to a single type of input. Today’s most capable models can process and reason across text, audio, images and complex data modalities such as spatial data, sensor streams, and population-scale genomics all within a single analytical framework. This shift is changing how humans interact with technology, enabling a more intuitive and context-aware experience that’s closer to conversing with a colleague than issuing rigid commands to a machine.
Modern AI systems no longer simply listen to spoken words or parse written text. They can interpret facial expressions, gestures, visual scenes, and environmental cues, then combine analysis of these signals to better understand intent and context. In scientific and technical domains, multimodal AI enables deeper analysis by aligning diverse datasets, such as imaging data with molecular profiles or spatial measurements with temporal signals.
What are multimodal AI models and why are they important?
In healthcare and life sciences, multimodal AI can combine medical imaging with genomic and clinical data to enable more precise disease characterization and patient stratification. Autonomous vehicles rely on multimodal models that fuse data types like camera feeds, lidar, radar, and high-definition maps to safely interpret dynamic environments. In robotics, integrating video, force sensors, and spatial data allows machines to adapt to changing physical environments and perform complex physical tasks.
Across these domains, multimodal AI enhances decision-making by expanding the context available to the model. By correlating signals across modalities, these systems deliver more reliable and useful outcomes than models constrained to a single data source.
How does multimodal AI work?
Multimodal AI works by integrating multiple types of data into a single learning and inference process, allowing models to reason across inputs rather than treating each modality in isolation. To start, images, text, sensor signals, genomic matrices and all kinds of other data types are processed with input modules that preserve their unique structure and meaning. Neural networks and deep learning algorithms then transform these diverse inputs into intermediate representations that can be aligned and combined.
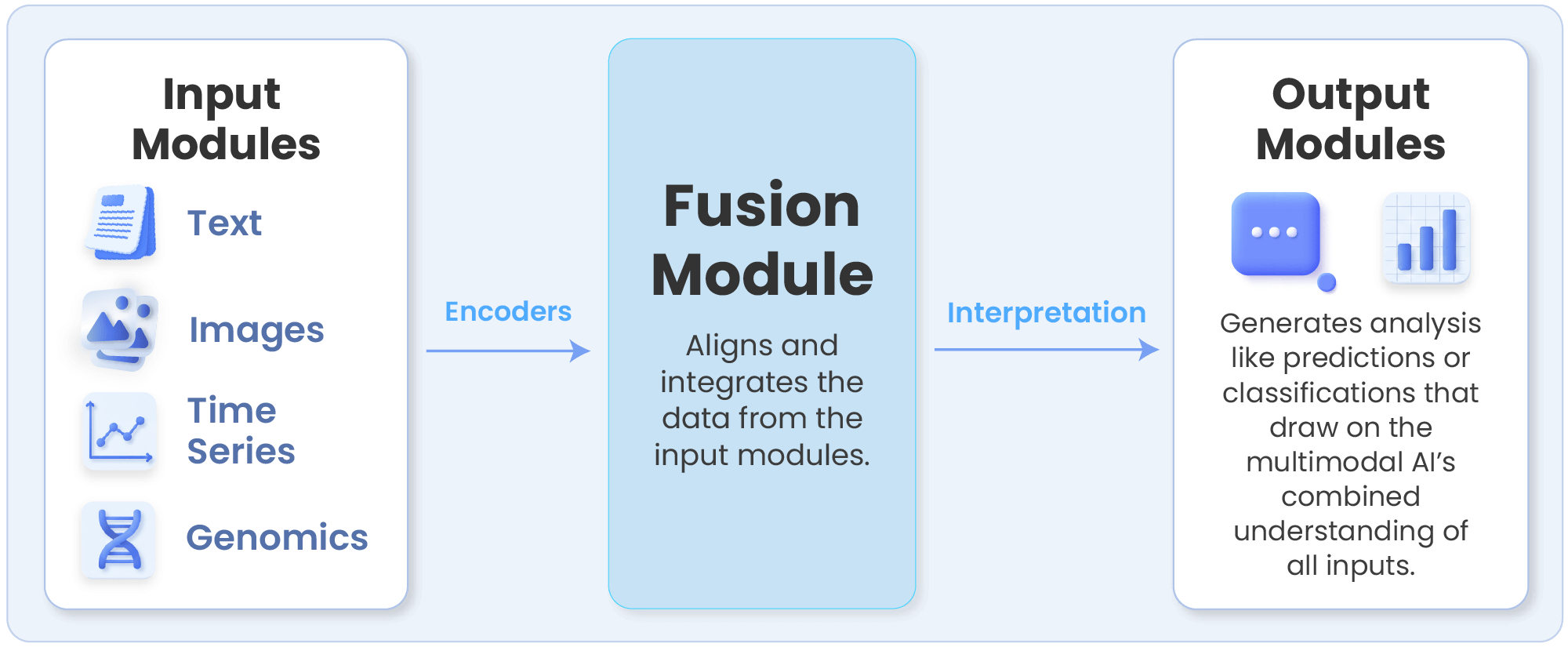
The result is AI that can make more informed predictions, reduce uncertainty, and adapt to real-world complexity. These capabilities are difficult or impossible to achieve when data remains siloed across separate pipelines and analytical tools, making a unified data layer essential.
The challenges of managing multimodal data for AI models
Managing multimodal data for AI goes beyond the challenges of traditional machine learning workflows by adding the complexity of diverse datatypes and infrastructure. Teams must work with highly diverse data types, each with different structures, access patterns, and performance requirements. Tabular data systems were not designed to support these mixed modalities and workloads, which often forces organizations to stitch together multiple tools and formats to analyze everything. The result is data fragmentation, complex integration pipelines, performance bottlenecks at scale, and significant overhead in day-to-day data management. Let’s examine each of these data management challenges.
Data Fragmentation
Multimodal datasets are typically dispersed across specialized storage systems. For example, images may live in object storage, text in document databases, sensor data in time-series systems, genomic sequences in domain-specific formats like VCF, and so on. This data fragmentation creates inefficiencies when teams need to analyze data jointly, as this requires constant movement, duplication, or transformation of data—and any of these actions can alter the data’s accuracy and make it hard for AI models to understand it. Over time, these silos make it difficult for multimodal AI to analyze all this data effectively to reproduce results or produce holistic insight.
Integration Complexity
Bringing multiple modalities together requires complex integration logic that sits outside the AI model itself. Aligning images with text, video with sensor streams, or molecular data with clinical records often involves creating custom pipelines, managing complex metadata, and other preprocessing work. These integrations slow model development, increase the risk of errors, and make it harder to adapt AI workflows as data sources evolve.
Performance Bottlenecks
In addition to contributing to data fragmentation, traditional storage systems also struggle to support the access patterns multimodal AI requires to analyze diverse data. This is especially acute when dealing with sensitive data like EHRs and genetic information. Large-scale queries that span different data types often become slow and inefficient, particularly when models need to retrieve fine-grained subsets of data during training or inference. As datasets grow, these performance limitations directly impact model throughput and how quickly they can turn around useful insights.
Overhead in Data Management
Relying on separate systems for each data type introduces significant operational overhead. Engineering teams must manage multiple storage technologies, data formats, and access controls, often duplicating effort across pipelines. Maintaining consistency, ensuring data quality, and scaling infrastructure becomes increasingly complex, diverting time and resources away from model development and innovation. Cost is also a concern, as inefficient data management often leads to extensive computing spend to enable AI models to analyze diverse datatypes.
Applications of multimodal AI in business
Businesses are adopting multimodal AI to diagnose complicated problems, improve customer experiences, streamline operations, and make more informed, data-driven decisions. By analyzing a wide variety of data types, multimodal systems provide a richer understanding of customers, environments, and processes. This enables organizations to move beyond siloed analytics and toward models that reflect real-world complexity and deliver more accurate insights and predictions.
In healthcare, multimodal AI is used to integrate complex data types like medical imaging, electronic health records, genomic data, and social determinants of health (SDoH) data to support earlier diagnoses and more personalized treatment strategies. These systems help clinicians and researchers correlate visual indicators with molecular and clinical signals, improving both care quality and research outcomes. For example, ConcertAI’s Patient360 is a data platform that creates a comprehensive, multimodal view of individual patients by linking diverse healthcare data sources like EHRs, medical claims, clinical variables abstracted from unstructured notes, social determinants of health to form a “360-degree” dataset for each patient.
In logistics and operations, companies leverage multimodal data from GPS, vehicle sensors, video feeds, and environmental inputs to optimize routing, predict equipment failures, and improve supply chain visibility. This integrated view enables faster, more resilient operational decision-making. One example of multimodal AI in this field is Seekr, which integrates multimodal satellite and sensor data with next‑gen Visual Language Models to enable rapid deployment of agentic AI that delivers actionable geospatial intelligence at scale.
In marketing and customer engagement, multimodal AI analyzes text, voice, and visual cues to better understand customer intent and sentiment. The result is more personalized interactions, dynamic content generation, and campaigns that adapt in real time based on user behavior across channels. For example, Google Gemini’s Conversational Agents can recognize vocal intonations, text inputs, and real-time video shared from user devices to help customers solve problems and find the services they need. This is an example of how agentic AI depends on multimodal inputs to function effectively.
Why multimodal AI is important for the future
Multimodal AI is fundamentally changing how organizations interact with technology, customers, and data. As businesses continue to generate increasingly diverse datasets, the ability to analyze multiple modalities together in a multimodal data platform will become essential. Future AI systems will not simply respond to isolated inputs, but will continuously synthesize signals from text, visuals, sensors, and domain-specific data to understand context, intent, and change in real time.
Multimodal AI also drives more natural human-computer interactions. Systems that can see, hear, and interpret context alongside language feel less like tools and more like collaborators, creating a seamless experience to better solve problems. As multimodal AI capabilities mature into omnimodal intelligence, organizations will be better equipped to maximize the potential of all their data by tackling multifaceted challenges, accelerating innovation, and building AI systems that reflect the full complexity of the real world instead of simplified slices of it.
How TileDB helps develop multimodal AI
TileDB supports the development of multimodal AI by providing a scalable database layer purpose-built for complex, multi-dimensional data. Rather than forcing diverse modalities into disconnected storage systems, TileDB enables teams to store and query data such as imaging, genomics, single-cell measurements, and other high-dimensional inputs within a single, unified framework. This approach simplifies data access across AI and analytics pipelines while preserving the structure and resolution required for advanced modeling. TileDB is also continuing to add native integrations with platforms like Databricks and Snowflake.
Designed for performance at scale, TileDB’s array-based architecture supports efficient querying, filtering, and parallel access, which are all capabilities critical for training and iterating on multimodal AI models. By reducing data movement and eliminating the need for custom integration layers, teams can spend less time managing infrastructure and more time developing models that learn across modalities. The result is a faster path from raw data to integrated insight, even as datasets continue to grow in size and complexity.
Conclusion: Embracing the full potential of multimodal AI
Multimodal AI represents a critical shift in how intelligent systems are built, moving beyond isolated data inputs to models that can reason across the full complexity of the real world. By combining signals from multiple data types, these approaches are already transforming industries such as healthcare and logistics, enabling more accurate insights, faster decisions, and more natural interactions with technology.
As data continues to grow in scale and diversity, the ability to manage and analyze multiple modalities together will become a defining capability for both businesses and research organizations. Teams that invest in the right data foundations will be best positioned to unlock the full potential of multimodal AI, accelerate innovation, and address increasingly complex challenges. Now is the time to explore how multimodal AI can be integrated into your workflows and drive meaningful impact.
To learn more about how TileDB can unlock the potential of multimodal AI and help your organization embrace omnimodal intelligence, contact us.
Frequently asked questions
What is the difference between multimodal AI and traditional AI?
Traditional AI models typically operate on a single type of data, such as text, images, or numerical features. Multimodal AI combines multiple data modalities within one model, allowing it to learn relationships across inputs and better reflect the complexity of real-world systems.
What’s the difference between LLMs and multimodal AI?
Large language models (LLMs) are primarily designed to process and generate text, learning patterns from vast language datasets. Multimodal AI extends beyond text by integrating additional data types such as images, audio, video, or sensor data, which allows these models to reason across multiple modalities and broader real-world context.
Are multimodal AI models more accurate than unimodal models?
Multimodal AI models are often more accurate because they draw on multiple sources of information. By correlating signals across different data types, these models reduce ambiguity and make better predictions than models limited to a single modality.
What industries can benefit most from multimodal AI?
Industries that rely on complex, heterogeneous data benefit most, such as healthcare and life sciences, autonomous systems, logistics, geospatial intelligence, robotics, and marketing. That said, any domain that combines visual, textual, sensor, or scientific data can gain deeper insights from multimodal AI.
Can multimodal AI be used for emotion recognition?
Yes. Multimodal AI can analyze facial expressions, voice tone, language patterns, and contextual signals together to infer emotional states more accurately than single-input systems, making it useful for customer engagement, mental health research, and human-computer interaction.
How does multimodal AI improve natural language understanding (NLU)?
Multimodal AI enhances NLU by grounding language in visual, auditory, or contextual data. This helps models better interpret intent, disambiguate meaning, and respond more accurately by understanding not just words, but the surrounding environment and signals.
Meet the authors