

Table Of Contents:
Introduction
What is multimodal data?
Multimodal Data Types and Characteristics
Applications of Multimodal Data
Challenges of Working with Multimodal Data
Multimodal Data Applications in the Life Sciences: Implementation and Technical Architecture
TileDB's Approach: Multimodal Data and the Life Sciences
Introduction
In this guide, we will cover multimodal data and its applications, challenges, and opportunities.
What is multimodal data?
Multimodal data is information that exists across multiple different formats or modalities simultaneously, including text, audio, image, video, and sensory or specialized data. Unlike traditional unimodal data, which is restricted to a single type of information, multimodal data integrates two or more of these diverse forms to provide a comprehensive representation of entities, events, or phenomena.
From a technical perspective, multimodal data presents significant design challenges because each modality has its own structure, scale, and semantic properties. For example, text data is typically processed as sequences of tokens, images as pixel matrices, audio as waveforms, and time series as sequential numerical values, each requiring different storage formats, preprocessing techniques, and analytical approaches.
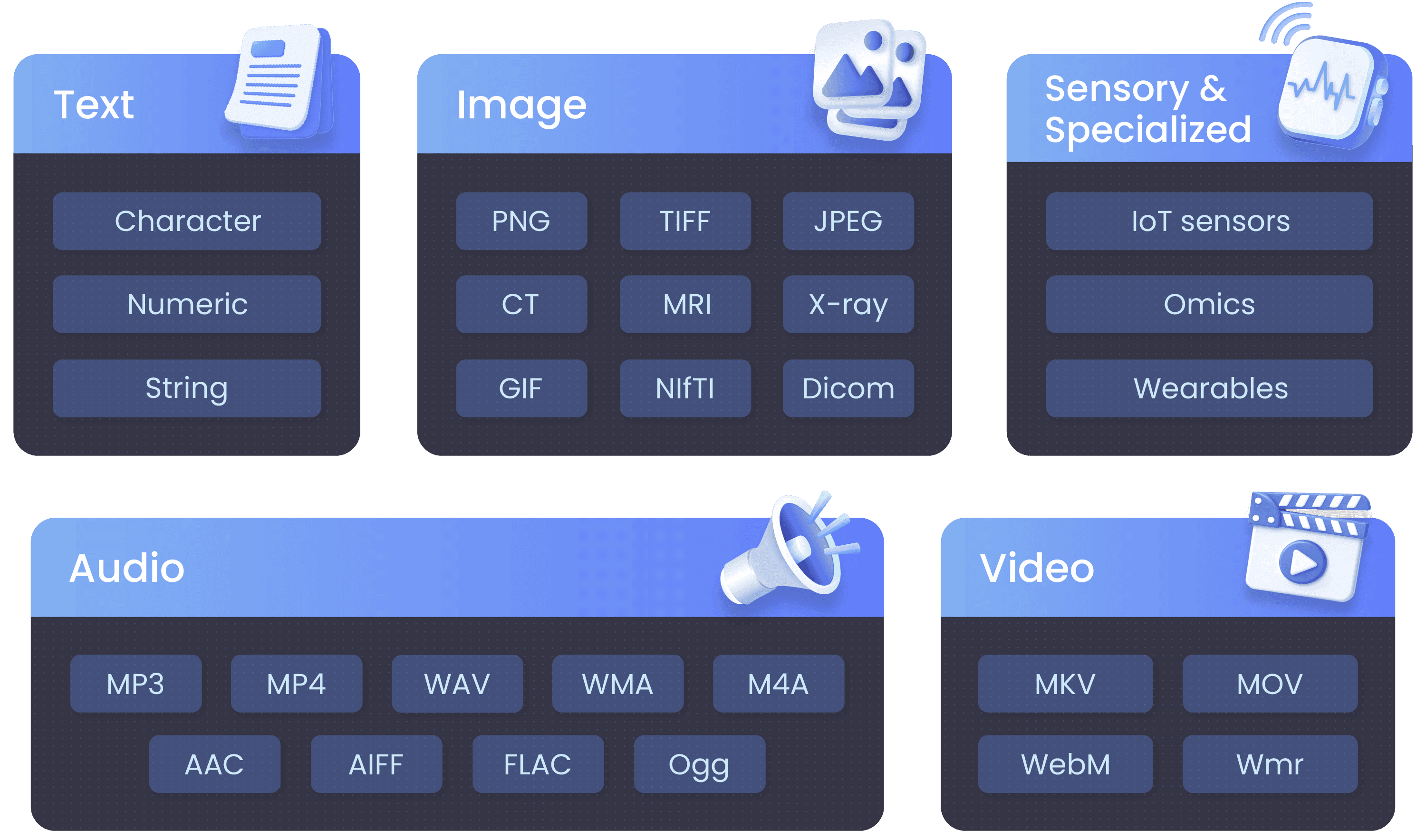
There are five primary data types: text, image, sensory & specialized, audio and video. Devices can generate different data formats. Some of these devices and the data formats they generate are included in the diagram.
Here’s what that looks like in the real world. A patient’s comprehensive healthcare record can include a combination of data types, formats, and structures:
Structured data: Demographics, lab results, medication history (tabular)
Unstructured text: Clinical notes, medical history (text)
Imaging data: X-rays, MRIs, CT scans (multi-dimensional arrays)
Time-series data: Vital signs, continuous glucose monitoring (sequential)
Genomic sequences: DNA/RNA data (specialized formats)
Each modality captures different aspects of the patient's health status. When analyzed in isolation, these data types provide limited insights, but when properly integrated, they enable a holistic understanding that powers precision medicine initiatives, improves diagnostic accuracy, and optimizes treatment plans.
Of course, most real-world entities and processes are inherently multimodal. Customer interactions span digital clicks, voice calls, and in-person visits. Manufacturing processes generate sensor readings, quality inspection images, and maintenance logs. Financial transactions include structured data, document scans, and communication records.
However, few modern data platforms are designed specifically to handle these diverse data types in a unified system, addressing technical complexities while enabling more effective integration and analysis.
If you are in the life sciences and are already exploring multimodal data platforms, this buyer’s guide could be a helpful resource.
Why are multimodal data important?
Multimodal data are important because most real-world phenomena produce data that can be captured across many modalities. These data can be recorded using many devices, such as cameras, sensors, and computed tomography (CT) scanners. For data scientists, AI developers, and others who work with data and technology, utilizing multiple types of data offers significant advantages in understanding real-world phenomena and building performant AI applications and systems. The more data you have to work with, the more accurate your resulting analysis and outcomes will be.
Consider a consumer’s interaction with a superstore that sells a wide variety of merchandise. The retailer can offer the consumer a membership in a rewards program and assign them a number to enter before making purchases, allowing the retailer to gather data about the customer’s preferred products. The retailer can gather video of that customer when they use a self-checkout machine in the store. If the customer interacts with a smartphone application that allows them to place orders online, they can collect and analyze data based on those interactions.
These are just a few of the many ways retailers can gather multimodal data. The retailer can use that data to offer customers products, pricing, and other incentives that appeal to them, thereby enhancing their experience and fostering brand loyalty. With each new type of data gathered, the retailer establishes a more complete view of the customer and can tailor their experience with the brand.
Strategic Business Value and Technical Advantages of Multimodal Data
Here are a few key ways that organizations can leverage multimodal data strategies for demonstrated, strategic business value:
Competitive differentiation: Create barriers to competition through insights unavailable from conventional single-modality approaches. Multimodal data can fuel innovative breakthroughs and new solutions to challenging problems by revealing hidden value from data.
A more complete decision context: Multimodal data provides executives and decision-makers with comprehensive information that incorporates multiple perspectives. For example, a customer intelligence platform that integrates purchase history, service interactions, and social sentiment can provide a 360-degree view that enables more effective engagement strategies.
Innovation acceleration: The integration of diverse data types often reveals previously invisible patterns and relationships, creating opportunities for product innovation, process optimization, and the development of new business models. Cancer researchers are using multimodal data to perform virtual biopsies, avoiding the need for invasive procedures and enhancing the accuracy of outcome predictions.
Enhanced risk management: Multiple complementary data sources provide earlier and more reliable risk signals across domains from cybersecurity to financial compliance. Financial institutions have implemented multimodal data systems that combine transaction patterns with behavioral biometrics for more accurate fraud detection.
Technical Advantages of Multimodal Data for AI
For people who develop and monitor AI systems, working with multimodal data offers significant technical advantages:
AI model performance: Models trained on diverse, complementary data types consistently outperform unimodal alternatives. A study on multimodal deep learning for solar radiation forecasting found a 233% improvement in performance when applying a multimodal data approach compared to using unimodal data.
Redundancy: Multimodal systems maintain performance even when one data source is compromised, damaged, or missing. This redundancy is crucial for applications that require high reliability, such as autonomous systems or medical diagnostics. Duke researchers found multimodal data redundancy could protect autonomous systems against an attack strategy that can fool vehicle sensors into perceiving nearby objects are closer (or further) than they appear.
Transfer learning opportunities: Knowledge gained from one modality can be transferred to improve performance in another, reducing the data requirements for new applications or domains.
Reduced model overfitting: Models trained on multiple data types are less likely to overfit to artifacts in any single modality, resulting in better generalization to new data. Technical implementations can leverage this property to create more deployable models with consistent performance across diverse operational conditions.
Multimodal Data Types and Characteristics
The key characteristics of multimodal data create both challenges and opportunities for data practitioners and organizational leaders. Understanding these properties is essential for effective system design and strategic planning.
Heterogeneity: Multimodal data encompasses fundamentally different information types with varying structures, formats, dimensions, and scales. This heterogeneity creates significant technical challenges for storage, processing, and analysis. For example, integrating textual medical records (unstructured, symbolic) with MRI scans (multi-dimensional arrays of pixel intensities) requires specialized approaches that traditional homogeneous data systems cannot support.
Complementarity: Different modalities capture complementary aspects of the same underlying phenomenon, providing a more complete picture when properly combined. For example, in autonomous vehicles, cameras capture color and texture information, lidar measures precise distances, and radar detects velocity. Each of these devices complements the limitations of the others. This complementarity is the primary source of the performance advantages in multimodal systems.
Correlation and alignment challenges: While meaningful relationships exist between different modalities, establishing these correspondences presents significant technical challenges. Temporal alignment (synchronizing data collected at different frequencies), spatial registration (mapping between different coordinate systems), and semantic alignment (connecting concepts across modalities) all require sophisticated techniques. For example, in manufacturing settings, aligning high-frequency sensor data with lower-frequency quality inspection results often requires specialized pre-processing and alignment algorithms.
Variable dimensionality: Different data modalities have inherently different dimensional structures. Text may be one-dimensional (sequences), images two-dimensional, video three-dimensional (including time), and scientific data can be multi-dimensional tensors. This dimensional diversity impacts storage architecture, indexing approaches, and computational requirements.
Quality variations: Quality, accuracy, and reliability typically vary across modalities, creating challenges for integration. In security systems that combine video surveillance with audio monitoring, visual data may be compromised in low-light conditions, while audio remains clear. This requires intelligent fusion approaches that dynamically weight modalities based on reliability.
Storage and computational intensity: Multimodal datasets often require substantially more storage and processing resources than unimodal alternatives. High-resolution medical imaging, genomic sequencing, or video analysis can demand terabytes to petabytes of storage and specialized computational architectures for efficient processing.
Domain-specific semantics: Each modality often has its own domain-specific meaning and interpretative frameworks. For example, in healthcare, genomic data follow biological semantics, while clinical notes utilize medical terminology, and imaging data require radiological interpretation, necessitating domain knowledge across multiple specialties.
These characteristics have profound implications for data architecture and the selection of technology. Some platforms are designed specifically to address these challenges through universal data models that can represent diverse modalities while maintaining performance, scalability, and analytical flexibility.
Architectural Considerations of Multimodal Data
When a team is working with more than two types of data, it’s likely they will need to work with more than one tech stack or set of platforms and tools where data are collected, stored, and accessed. For technical teams, each multimodal data type requires specific architectural considerations, including:
- 1
Storage strategy: Different modalities have vastly different storage requirements. Text is relatively compact, while high-resolution images, video, or genomic data can be extremely storage-intensive.
- 2
Processing pipelines: Each modality typically requires specialized preprocessing techniques to be applied before integration.
- 3
Integration approach: The method of combining modalities (early, late, or hybrid fusion) has a significant impact on system design and performance.
- 4
Query optimization: Efficient querying across heterogeneous data types requires specialized indexing and query planning.
For executives, understanding these types helps prioritize investments and set realistic expectations for multimodal data initiatives.
TileDB is designed to handle diverse data types within a single platform, addressing the technical complexities while enabling more effective business applications. Contact us to get a demonstration.
Applications of Multimodal Data
Multimodal data encompasses various combinations of different data types, each presenting unique technical challenges and business opportunities. Understanding these types enables organizations to plan effective data architectures and analytical approaches.
Data Types | Description and Technical Considerations | Business Applications |
|---|---|---|
Text and Image | Combines textual data with visual information. Requires bridging natural language processing (NLP) and computer vision techniques. Technical challenges include cross-modal alignment and representation learning. Storage requirements: moderate to high, depending on image resolution. | • E-commerce product listings with images and descriptions • Medical records with diagnostic images and clinical notes • Technical documentation with explanatory diagrams • Social media posts with text and attached photos |
Audio and Visual | Merges acoustic data with visual information. Demands synchronized processing across time dimensions. Technical challenges include temporal alignment and handling different sampling rates. Storage requirements: high, especially for high-definition video. | • Video conferencing with speech and facial expressions • Media monitoring for brand mentions in broadcast content • Security systems combining video surveillance with audio detection • Customer service interactions with both verbal and non-verbal cues |
Time Series αnd Categorical | Pairs sequential numerical measurements with discrete classifications. Technical challenges include handling different temporal granularities and integrating continuous and discrete data types. Storage requirements: variable, but typically moderate. | • Manufacturing sensor data with equipment status labels • Financial transactions with risk categories • Patient vital signs with diagnostic codes • Website analytics with conversion event classifications |
Multiomics | Integrates different biological data types in life sciences. Technical challenges include high dimensionality and complex biological relationships. Storage requirements: extremely high, often at petabyte scale. | • Drug discovery combining genomic, proteomic, and clinical data • Disease research integrating multiple biological layers • Personalized medicine combining patient-specific biological markers • Biomarker discovery across multiple data types |
Sensor Fusion | Integrates data from multiple physical sensors. Technical challenges include real-time processing requirements and varying reliability across sensors. Storage requirements: high, especially for continuous monitoring. | • Autonomous vehicles (cameras, lidar, radar, GPS) • Industrial IoT (temperature, vibration, acoustic, pressure) • Smart city infrastructure (traffic, air quality, noise, weather) • Wearable health devices (heart rate, movement, temperature) |
Spatiotemporal | Combines location information with time-based data. Technical challenges include specialized indexing for efficient queries across both dimensions. Storage requirements: moderate to high, depending on resolution. | • Supply chain tracking and optimization • Epidemiological disease spread monitoring • Weather pattern analysis and prediction • Urban mobility and transportation planning |
Challenges of Working with Multimodal Data
Working with multimodal data presents significant challenges that organizations must address through both technical solutions and organizational strategies. Understanding these challenges enables technical teams to plan effective implementations, while allowing executives to set realistic expectations and allocate appropriate resources.
Technical Challenges and Examples
Data integration complexity: Combining fundamentally different data types with varying structures, formats, dimensions, and scales presents substantial technical difficulties.
For example, a healthcare organization with a precision medicine mandate may face this challenge when attempting to integrate genomic data (massive, specialized formats) with clinical records (structured and unstructured) and medical imaging (multi-dimensional). Implementation could require:
Custom ETL pipelines for each data modality
Specialized storage architectures optimized for each data type
Common metadata framework linking diverse information
Ontology mapping to standardize terminology across domains
Storage and computational requirements: Multimodal data, particularly when involving high-resolution imagery, video, or scientific data, demands enormous storage capacity and computational resources.
For example, a typical intelligent vehicle can generate 5-20TB of sensor data daily, requiring:
Distributed storage architecture
Tiered storage strategy (hot/warm/cold data)
Parallel computing infrastructure
Edge processing for real-time components
Specialized hardware for different processing needs (GPUs, FPGAs)
Quality and alignment inconsistencies: Data quality often varies significantly across modalities, with different noise profiles, missing data patterns, and reliability characteristics. Temporal and spatial alignment between modalities presents additional challenges.
For example, a manufacturing company implementing multimodal quality control could face misalignment between:
High-frequency sensor readings (millisecond intervals)
Lower-frequency quality inspection results (minutes)
Maintenance logs (daily/weekly records)
Addressing these inconsistencies required sophisticated synchronization algorithms and data quality assessment frameworks.
Specialized expertise requirements: Effectively working with multimodal data requires expertise across multiple domains and technologies. Organizations often struggle to find talent with the breadth of knowledge needed to work across text analytics, image processing, time-series analysis, and other specialized techniques.
Organizational Challenges
Data silos and ownership issues: Different modalities often originate in different departments with separate owners, technologies, and governance processes. Breaking down these silos requires organizational change management as much as technical integration.
ROI justification complexity: Multimodal data initiatives typically require significant upfront investment before delivering business value. Executives often struggle to develop compelling business cases with traditional ROI frameworks.
Governance and compliance complexity: Different data types may be subject to varying privacy regulations and security requirements. For example, a financial services firm implementing multimodal KYC (know your customer) could face distinct regulatory requirements for:
Biometric data (requiring explicit consent)
Transaction information (subject to financial regulations)
Document images (with personally identifiable information)
Communication records (with varying retention requirements)
Scaling and productionization: Moving multimodal systems from proof-of-concept to production introduces new challenges in operational reliability, monitoring, and maintenance. Organizations often underestimate the complexity of operationalizing multimodal data pipelines.
Implementation Approaches
Organizations can address these challenges through:
- 1
Phased implementation: Beginning with integration of two complementary modalities before expanding to more complex combinations
- 2
Unified data platforms: Adopting technologies like TileDB that are specifically designed to handle diverse data types within a single system, reducing integration complexity
- 3
Composable architecture: Building modular data pipelines that can be reconfigured for different modality combinations
- 4
Cross-functional teams: Creating integrated teams that combine domain expertise with data engineering and data science capabilities
- 5
Governance frameworks: Developing comprehensive data governance approaches that address the specific requirements of multimodal data
For executives, understanding these challenges helps set realistic timelines and resource allocations. For technical teams, anticipating these obstacles enables more effective architecture and implementation planning.
Multimodal Data Applications in the Life Sciences: Implementation and Technical Architecture
Life sciences organizations are at the forefront of multimodal data integration, combining diverse biological and clinical data types to accelerate research, improve patient outcomes, and develop breakthrough therapies. This sector demonstrates both the transformative potential and technical challenges of effectively managed multimodal data.
Technical Implementation
Modern life sciences research generates unprecedented volumes and varieties of data. A typical multi-omics pipeline might include:
Genomics: DNA sequencing data (FASTQ/BAM/VCF formats, terabytes per sample)
Transcriptomics: RNA expression measurements (matrices, arrays)
Proteomics: Protein abundance/modification data (MS data)
Metabolomics: Small molecule profiles (chromatography data)
Imaging: Microscopy, radiological imaging (DICOM, proprietary formats)
Clinical: Electronic health records, trial data (structured and unstructured)
The technical architecture for managing this diverse data typically includes several layers, with each providing key capabilities for multimodal data:
- 1
Storage: Specialized repositories for each data type with appropriate compression and access patterns
- 2
Integration: Data harmonization services with standardized metadata models
- 3
Analysis: Modality-specific and cross-modal analytical pipelines
- 4
Governance: Controls for sensitive patient data and intellectual property
Implementation challenges include the extreme scale of certain modalities (for example, genomic sequencing can generate terabytes of data per sample), standardization across proprietary instruments and formats, and the need for specialized expertise spanning both data science and biological domains.
Scientific Applications
The integration of multimodal data has transformed numerous life sciences disciplines:
Genomic medicine: Studies such as the Cancer Genome Atlas (TCGA) have analyzed over 20,000 primary cancer samples across 33 cancer types using multiple genomic platforms, leading to the identification of novel molecular subtypes and potential therapeutic targets. This work required sophisticated data management approaches to handle petabytes of multimodal data generated by diverse sequencing and analytical platforms.
Drug discovery: Pharmaceutical companies combine chemical structure information, target binding affinity data, gene expression responses, and clinical outcomes to identify promising compounds. Harvard University research published in March 2025 demonstrated that a multimodal AI model combining structural, pathway, cell viability, and transcriptonomic data improved the prediction accuracy of clinical outcomes of drug combinations by up to 22.5% compared to single-modality approaches. The model predicted drug combination effects across 953 clinical outcomes and 21,842 compounds, including combinations of approved drugs and novel compounds in development.
Precision medicine: Initiatives like the National Institutes for Health’s (NIH) All of Us Research Program collect genomic, electronic health record, environmental, and lifestyle data from diverse participants to build comprehensive multimodal datasets for advancing personalized health interventions. These programs generate petabyte-scale heterogeneous datasets that require specialized management approaches.
Single-cell biology: Recent advances in single-cell technologies generate unprecedented views of cellular heterogeneity by simultaneously measuring multiple molecular features of individual cells. The Human Cell Atlas project, for example, combines single-cell RNA sequencing, ATAC-seq, spatial transcriptomics, and imaging data to create comprehensive cellular maps, requiring sophisticated data integration techniques.
TileDB's Approach: Multimodal Data and the Life Sciences
TileDB's universal database platform specifically addresses the challenges of working with multimodal data by handling diverse data types within a single system, eliminating silos while providing the performance and scalability required for enterprise deployment.
For example, many organizations in the life sciences industry use TileDB's platform to address critical challenges in multimodal data management:
Unified data management: For genomics applications, TileDB efficiently stores and processes massive sequencing datasets alongside clinical measurements and metadata. Its sparse array technology is particularly well-suited for representing genomic variants, while the platform's ability to handle both structured and unstructured data enables seamless integration of diverse biomedical data types.
Performance at scale: TileDB's architecture is designed to handle the extreme data volumes characteristic of modern life sciences research, from high-throughput sequencing to high-resolution imaging. The platform's cloud-native design enables distributed processing across computational resources without data movement.
Collaboration infrastructure: TileDB provides the technical foundation for secure data sharing and collaborative research across institutions, addressing a critical need in multi-center studies that require the integration of data from diverse sources.
Future-proof architecture: The life sciences field continuously develops new experimental technologies and data types. TileDB's flexible data model can adapt to emerging modalities without requiring fundamental architectural changes.
Meet the authors
