

Table Of Contents:
What is a trusted research environment (TRE)?
Why does the life sciences industry need trusted research environments?
What are the core pillars of a trusted research environment?
What are the key benefits of trusted research environments for pharma and biotech?
What’s next for trusted research environments in pharma and biotech?
How does TileDB support the future of trusted research environments?
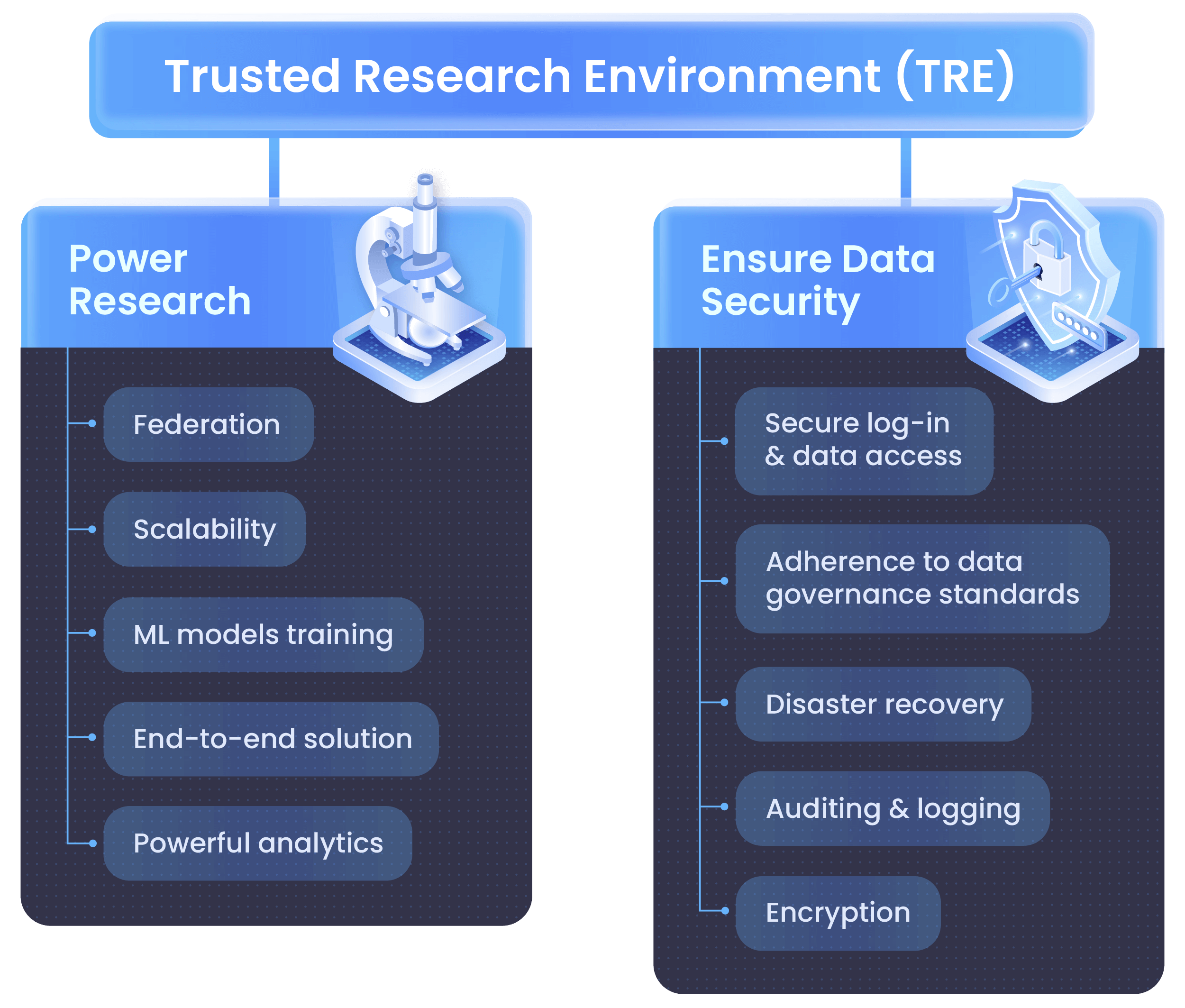
A trusted research environment (TRE) refers to highly secure and controlled computing infrastructure designed to give approved researchers remote access to sensitive biomedical data while protecting patient confidentiality. TREs are important to life sciences research because they provide safe remote access to useful data without compromising privacy or security. The core pillars of TREs are known as the 5 Safes framework, which are safe people, safe projects, safe settings, safe data, and safe outputs.
The primary benefits of trusted research environments include faster time to insights across modalities, improved reproducibility and traceability for life sciences data, and reduced infrastructure complexity and cost. Among the best practices of TREs are to prioritize cloud-native and scalable architecture, integrate with existing tools and pipelines, and enable secure real-time collaboration across teams. Future trends to watch with TREs include new data governance standards for how researchers should operate TREs. Let’s explore the vital role of TREs for life sciences research.
What is a trusted research environment (TRE)?
A trusted research environment (TRE) is a secure computing environment built to offer safe remote access to sensitive data while keeping that data private. Also called “data safe havens,” “data clean rooms” or “secure data environments,” trusted research environments help meet the growing need for secure collaborative environments in biomedical research. Today, such researchers have found immense potential in large-scale genomic data such as the 500,000 genomic samples in UK Biobank. In the past such sensitive genetic information was often stored in institutional silos, but these silos protected patient confidentiality but were difficult to access for researchers outside these organizations.
TREs address this problem by creating secure and collaborative environments in the cloud that enable remote access to approved researchers without compromising data security or privacy. Global healthcare and life sciences firms now rely on TREs as a secure solution for the sharing of genomic and clinical datasets inside and outside their organizations for research purposes. Next, we will examine why the life sciences industry needs TREs more than ever.
Why does the life sciences industry need trusted research environments?
Traditional research environments were simply never designed to handle the volume and complexity of biomedical data like whole-genome sequencing, multi-omics, medical imaging, electronic health records (EHRs) and single-cell data. Analyzing and sharing these large datasets require unified platforms built with proper security, interoperability and governance. Siloed storage infrastructure not only struggles with these key capabilities, but often cannot even store this data efficiently. Tool sprawl only compounds the issue, as researchers often create bespoke solutions for data analysis that each require their own access protocols, compliance checks and compute infrastructure. As a result, organizations face long onboarding times, siloed expertise, repetitive data wrangling tasks and inefficient workflows that slow down time-to-insight and reduce ROI.
What are the core pillars of a trusted research environment?
The core pillars of a trusted research environment are known as the Five Safes Framework: safe people, safe projects, safe settings, safe data and safe outputs. Each of these safe principles has a key role to play in ensuring strong governance, secure collaboration and effective risk mitigation in pharma and biotech research.
Safe people: Trust begins with the researcher
The safe people principle means only appropriately trained and qualified individuals can access data from sensitive sources. This protects health data by ensuring only researchers and analysts with the proper credentials and education can use the trusted research environment. To ensure this, TREs enforce identity verifications, secure logins and onboarding processes that make sure users grasp their legal and ethical responsibilities around sensitive data.
Example: A genomic research project may require users to complete data handling certifications and receive explicit approval from an institutional review board (IRB). The project also maintains governance processes that only allow verified users to access specific datasets within the TRE, preventing unauthorized parties from handling sensitive information.
Safe projects: Clear and ethical purpose
The safe projects pillar requires that data may only be used for approved research that aligns with ethical and scientific standards and has clear public benefit. If a project does not have a clearly-defined purpose that fits with ethical scientific goals or if data is repurposed beyond its original intent, it is not a safe project. TREs ensure safe projects by reviewing project proposals to ensure they serve legitimate public interest and comply with relevant regulations.
Example: Before researchers at a big pharma organization can gain access to linked clinical and genomic data, they must submit a study protocol to the firm’s compliance experts that describes their scientific aims and intended analyses. The compliance reviewers only grant TRE access to projects that meet governance criteria, helping protect sensitive patient data.
Safe settings: Controlled and monitored environments
The safe settings principle mandates that data can only be accessed inside a secure technical environment that strictly controls where data is stored, used and analyzed. This reduces risk and protects patient privacy through secure technology with strong oversight. TREs create safe settings through cloud-based or on-premises secure enclaves that are fully auditable, isolated from unauthorized access and equipped with automated compliance controls.
Example: A cloud-based TRE at a biotech firm might use virtual desktops that block copy/paste, disable internet access and log every action taken within the workspace. These compliance controls ensure sensitive data never leaves the secure setting of the TRE and provide traceability for all user activity.
Safe data: Protect privacy by design
The safe data pillar requires that all research data has been made completely anonymous to protect patient privacy. This makes sure that the only research data that enters a TRE is de-identified to make it private by design. TREs ensure safe data through data protection practices like pseudonymization, tokenization and differential privacy to keep individuals from being identified even when multiple datasets are linked.
Example: Before integrating EHR and imaging data into a TRE, a life sciences firm strips out personally identifiable information (PII) and replaces any unique identifiers with tokens. Depending on the risk profile, the researchers may apply advanced privacy protection techniques like k-anonymity or differential privacy for additional risk mitigation.
Safe outputs: Validate results to prevent disclosure of sensitive data
The safe outputs principle means that all research results are reviewed to ensure they do not disclose sensitive or identifiable information. This pillar is a final safeguard to confirm no research outputs inadvertently identify any subjects. TREs often use automated tools that scan research outputs like tables, charts or models for potential disclosure risks, and compliance experts manually review these materials to confirm no residual data could breach privacy.
Example: A research team at children’s hospital analyzing rare disease prevalence may generate summary statistics. Before those results leave the environment, output-checking protocols flag small cell sizes (such as patient counts < 5) that could risk patients being accidentally re-identified. The TRE blocks export of these outputs until researchers correct or redact the flagged results.
What are the key benefits of trusted research environments for pharma and biotech?
Faster time to insights, improved traceability, more efficient infrastructure and streamlined collaboration are all key benefits that trusted research environments provide for pharma and biotech firms. As research leads look for ways to improve team workflows and business outcomes across their research operations, here are four key ways that TREs provide a strong return on investment:
Faster time to insights across modalities
Scenario: A translational research team can run integrated analyses on RNA-seq, digital pathology slides and longitudinal EHR data inside a single TRE workspace. This helps them rapidly iterate on insights that would have taken weeks or months in distributed environments.
Improved reproducibility and traceability
Being able to easily reproduce research results and analyses is a cornerstone of scientific integrity. TREs enforce reproducibility by design with features like audit trails, version control and data lineage tracking. These capabilities ensure every data point, transformation and model can be easily traced back to its source. This level of traceability is critical not only for compliance and publication, but also for internal quality assurance in regulated environments like clinical trials or FDA submissions.
Scenario: To improve the quality of rare disease regulatory applications, the US FDA funded the rare disease cures accelerator data analytics platform (RDCA-DAP). This platform focuses on increasing data sharing and collaboration among the entire rare disease ecosystem,
securely connecting rare disease research teams with diverse data streams and tools to accelerate breakthroughs.
Reduced infrastructure complexity and cost
The diversity of different research processes and data formats often leads to tool sprawl and infrastructure duplication for life sciences organizations. TREs helps these firms reduce their infrastructure complexity and cost by consolidating data access, compute resources and analysis tools into a single governed environment, often on clouds like AWS. With TREs, teams no longer need to manage separate pipelines for different data types or maintain redundant compute clusters. This eliminates duplication and lowers IT overhead while also simplifying user training to dramatically improve total cost of ownership.
Scenario: Instead of setting up separate VMs and storage for each therapeutic area or partner project, a pharma research firm can run all their studies within a single TRE instance on Amazon S3 that scales elastically while maintaining compliance boundaries.
Enabling collaborative and cross-functional research
Scenario: The European Prospective Investigation into Cancer Norfolk study (EPIC-Norfolk) is part of a large multicenter cohort study offering de-identified lifestyle and health data from more than 30,000 people to help identify potential causes of cancer. To enable researchers across the world to access this data securely, EPIC-Norfolk relies on a TRE known as the Secure Research Computing Platform (SRCP). This provides remote access to a secure analytics environment so researchers bring their analysis to the data without removing it from the environment, and results are checked to ensure they fit the research objectives.
What best practices should you follow for a trusted research environment?
Implementing a Trusted Research Environment (TRE) starts with deploying secure infrastructure, but that’s only the beginning. Your TRE should be a platform that empowers researchers and data scientists to easily do their best work while simplifying security and compliance. Implement your TRE poorly, and you could introduce friction across the research cycle, hinder collaboration and fail to deliver on their promise of secure and scalable science.
To ensure long-term success for their TREs, life sciences organizations should follow six best practices designed to optimize performance and streamline workflows while future-proofing the TRE for evolving needs.
1. Prioritize cloud-native and scalable architecture
Life sciences research increasingly depends on high-throughput sequencing, multi-omics analysis and large-scale imaging. This means your TRE needs elastic, compute-intensive infrastructure that can easily handle large and diverse datasets. A cloud-native TRE can dynamically scale to handle spikes in workload and ever-growing datasets without suffering any degradation to performance.
For example, a genomics company working with terabytes of raw sequencing data could use a cloud-native TRE to automatically scale storage and parallelize compute for genome-wide association studies (GWAS), reducing turnaround time from days to hours.
2. Integrate with existing tools and pipelines
Every experienced researcher has their favorite analytics tools, frameworks and platforms to do their best work. When you adopt a TRE, you are more likely to gain buy-in from your research team if they don’t have to abandon familiar tools or rewrite existing workflows. Seamless interoperability with languages like R and Python, as well as tools like Jupyter, Nextflow, or Galaxy reduces user friction and boosts adoption for faster time-to-value.
If a clinical analytics team integrates their existing pipeline for survival analysis into their TRE without forcing extensive modification, their statisticians can continue using R scripts and preferred libraries while staying within a governed environment. This adds the security advantages of a TRE without disrupting their established workflow.
3. Support multiple data modalities
Modern biomedical research relies on a wide variety of data types, from structured clinical records to semi-structured lab files to unstructured imaging and pathology data to data formats currently under development. For your TRE to be useful long into the future, it must support ingestion, indexing and querying across multiple modalities while being open to new data types as they emerge.
For instance, a translational research team investigating cancer subtypes needs to be able to jointly analyze EHRs, whole-exome sequences and histopathology images inside a unified TRE workspace. If their TRE did not support one of these modalities, the team would struggle to analyze all the data they needed.
4. Implement strong access controls and auditing
TREs are only as trustworthy as the policies that govern them. To equip your TRE with the security it needs, use access control with fine-grained permissions and logging. This ensures users can only see the data they are authorized to use, and simplifies auditing to ease regulatory compliance.
For example, a biotech firm implements an access control system in their TRE that enforces project-level permissions based on role. This ensures a CRO has access only to de-identified imaging data for one study while full clinical datasets remain restricted to internal staff. And because all actions are logged for all users, the firm is always ready for regulatory audits.
5. Enable real-time collaboration across teams
6. Plan for future AI and ML workflows
As AI and machine learning unlock new possibilities in life sciences, your TRE must be ready to support AI model training, validation and deployment. This means designing your TRE infrastructure with AI and ML in mind by including GPU acceleration, model versioning and secure handling of training data. It’s also important to ensure your research data follows FAIR data principles by being findable, accessible, interoperable and reusable.
Consider this scenario: A biotech company uses their TRE for exploratory omics research as well as training machine learning models to predict treatment response. This requires them to design an environment that supports TensorFlow and PyTorch as well as audit trails for model reproducibility.
How are TREs used in real-world life sciences applications?
Trusted Research Environments (TREs) are becoming essential infrastructure in life sciences, helping to transform data management and research. Leading pharmaceutical, biotech and public health organizations are adopting TREs to simplify compliance, accelerate discovery, enable secure collaboration and better manage ever-growing volumes of sensitive data. Here are three real-world use cases that illustrate the diverse and high-impact applications of TREs.
- 1
The UK Biobank is a public health organization that created a publicly available biomedical database containing de-identified genomic information from 500,000 individuals to empower global researchers. The UK Biobank allows users to freely download analyses and aggregate metrics from its genomic data, but researchers can only access the database itself inside the UK Biobank’s secure cloud-based TRE.
- 2
The Yale University Open Data Access (YODA) Project advances the responsible sharing of clinical research data by providing global researchers no-cost access to data from 491 pharmaceutical trials. The YODA TRE enables approved researchers outside these pharma partners to draw on its databases to pursue their own research projects while maintaining the confidentiality of patients through de-identification.
- 3
The BeginNGS organization is developing a list of actionable genetic disorders, target genes and variants of interest related to rare diseases in newborns. The BeginNGS consortium relies on TileDB for its variant warehouse and trusted research environment, using TileDB to handle their Variant Call Format samples in a 3-dimensional array on Amazon S3 so their data can be analysis-ready and secure on cloud storage.
What’s next for trusted research environments in pharma and biotech?
As research teams plan their infrastructure strategies around secure remote collaboration, TREs will play an increasingly critical role. Trends to watch around TREs include the growing complexity of data harmonization amidst changing regulations as well as the emerging priorities of facilitating ML and AI technology in life sciences, implementing FAIR data principles and exploring federated learning.
As life sciences researchers gather multi-omics, imaging, EHR and other multimodal data from disparate sources, TREs will be vital to harmonizing these inputs into usable and context-rich datasets. TREs provide a governance-first foundation to address this challenge that enforces standards for remote access and auditability without sacrificing performance. With evolving privacy regulations like HIPAA and SOC-2, TREs will be essential to supporting secure research while mitigating regulatory risk.
AI and machine learning are reshaping life sciences research, offering “pharma companies a once-in-a-century opportunity” according to McKinsey. From predictive models for patient stratification to generative approaches for protein design, AI and ML opportunities offer immense potential while requiring substantial infrastructure resources. TREs must evolve in kind to support GPU-enabled compute, ML workflows and massive parallelism so data scientists can run AI training jobs securely. It’s important to remember TREs are not only about safeguarding data—they also can unlock its full analytical potential. Life sciences organizations that design their environments with AI-readiness in mind will be better positioned to accelerate discovery and drive competitive advantage.
A key element of AI-readiness is having TREs that embrace FAIR data principles, which ensure data is Findable, Accessible, Interoperable and Reusable. If research data is not FAIR, it is not usable by AI and ML applications. This in mind, TREs are ideal infrastructure to operationalize FAIR principles because they help centralize metadata, apply consistent schemas and automate access permissions.
Another key trend for using AI and ML in trusted research environments is federated learning. Federated learning is a decentralized machine learning approach where multiple entities collaboratively train a model without sharing their raw data. This is transforming life sciences research by enabling cross-institutional AI development while keeping sensitive data in its original location in compliance with privacy rules. By supporting secure computation across siloed datasets while preserving privacy and compliance, TREs serve as a trusted foundation for federated analytics.
How does TileDB support the future of trusted research environments?
As a database designed for discovery, TileDB was built to help biotech and pharma organizations unlock the potential of their TREs. Let’s walk through four key ways that TileDB supports the future of TREs through secure, scalable, simplified and collaborative technology.
- 1
TileDB unifies multi-modal data inside a highly scalable platform. Your TRE needs to be able to easily manage large datasets with many modalities. That’s why TileDB’s multi-dimensional arrays adapt to natively capture the structure of any data from any modality. This not only simplifies ingest for your TRE, but also makes it easy to analyze multimodal data at scale without hurting performance.
- 2
TileDB simplifies data infrastructure to reduce technical debt and tool sprawl. You want your TRE to speed up research processes without adding more sprawl to your data infrastructure. TileDB supports this goal through a native distributed, serverless compute engine that uses parallel algorithms and task graphs to implement complex workflows while optimizing compute and storage costs. In addition, TileDB lets researchers use their favorite tools like Jupyter notebooks inside our platform, which is pre-configured with the necessary libraries and resources for any scientific analysis.
- 3
TileDB empowers secure remote collaboration through federated queries. Balancing the need for easy remote access through FAIR principles with protecting sensitive data is a critical challenge for your TRE. TileDB enables secure remote collaboration using asset views that facilitate access to your massive datasets across multiple teams and projects without moving or duplicating the physical data on cloud storage. This makes it easy to control access to data with our teamspaces feature, which tracks and audit access history from dataset queries and writes, including statuses, logs and resource consumption. The result? You can trust all processing and storage of your data is secure in our SOC-2 and HIPAA compliant system of record.
- 4
TileDB facilitates future readiness for AI and ML applications. To ensure your TRE accelerates research processes over the long term, you want to design it with AI and ML applications in mind. TileDB can optimize your TRE’s readiness for AI/ML by centralizing and cataloging all your data regardless of format to train robust and comprehensive AI/ML models. We also make it easier to store access and version-controlled models alongside the data used to train them inside the same system of record. And with TileDB’s built-in, native vector search capability, your AI infrastructure will find data faster for faster learning and better results.
If you have more questions about designing a future-proofed trusted research environment for your research teams, TileDB is happy to help. Contact us today to start planning your TRE.
Meet the authors