
Table Of Contents:
Why legacy data infrastructure is failing healthcare and life sciences
How an omnimodal platform empowers healthcare and life sciences
TileDB Carrara: The omnimodal intelligence platform for healthcare and life sciences
The struggle to make the most of multimodal data has become the chief challenge of life sciences and healthcare. To some degree, this is understandable because of the inherent complexity of data like genomic variant files (VCFs) and single-cell datasets. But too often, the data infrastructure that life sciences organizations rely on cannot manage multimodal data that isn’t in tabular formats. The unfortunate result is that too much valuable data is siloed across disparate systems, preventing researchers from analyzing their multimodal data together.
To unlock the optimal health outcomes that multimodal data can make possible, we need a new approach that unifies multimodal data both as it is and as it will evolve. This omnimodal infrastructure can capture all of today’s data while embracing how such data will change in the future, providing a forward-looking foundation that embraces agentic AI as a new modality. This blog will examine why this omnimodal approach to data has become essential, and how a data platform with omnimodal intelligence can empower healthcare.
Why legacy data infrastructure is failing healthcare and life sciences
With about 30% of the world’s data volume being generated by the healthcare industry, it’s tempting to conclude the primary challenge of healthcare data is managing its massive volume. However, the core data management problem in healthcare is not size, but variety. Healthcare data includes modalities ranging from radiology images to EMRs to videos of surgeries to genomics databases. In addition, healthcare data is also subject to standards like DICOM (the global standard for medical imaging data) and FHIR (an interoperability standard to facilitate the rapid and secure exchange of protected health information).
All this healthcare data has value, but to find that value clinicians and researchers need to be able to analyze these data types together and look for connections and insights. Data infrastructure like cloud storage and database software play a key role in organizing and managing all this multimodal healthcare data. The trouble is, since the early days of databases like Oracle V2 and IBM DB2, most data infrastructure relies on tabular databases. These are designed for data that’s been structured in tables, such as Parquet or Iceberg files, but struggle to manage other data types like PDFs, video, images, omics or audio files.
All these nontabular healthcare data types get labeled as “unstructured,” which often means they are added to object storage without metadata and put to the side until they can be structured into tables. When legacy data infrastructure tries to manage such data types, the results are mixed. Some formats, such as select genomic and imaging standards, can be managed with legacy data platforms using specialized tools and frameworks—so long as these add-ons are used securely in a trusted research environment. Other complex modalities like single-cell data face severe problems of scale when researchers and data scientists try to manage and analyze millions of files on tabular data platforms.
The sad result is that healthcare and life sciences organizations end up relying on siloed data infrastructure that tries to force together tabular, bespoke and DIY solutions, along with separate catalogs and data governance systems. This not only raises the costs and complexity of their data infrastructure, but also slows the pace of discovery to a crawl.
This unfortunate status quo persists even as the pharma industry is expected to increase investment in AI and machine learning by 600% in the next few years. AI and agentic AI have built a dream for healthcare and life sciences organizations hoping to gain unprecedented insights from all the multimodal data they have been amassing. But AI is only as powerful as the data foundation supporting it. If healthcare data is trapped in disparate silos, inconsistently governed or otherwise inaccessible to AI platforms, even the most sophisticated AI agents will be unable to analyze this multimodal data.
How an omnimodal platform empowers healthcare and life sciences
The path forward for healthcare and life sciences organizations is to unify all their data silos in an omnimodal platform that treats all data as modalities. This means that every data type—from clinical notes to MRI images to AI agents—is made discoverable, securely accessible and easy to analyze inside one platform. Instead of siloing data based on whether or not it had tabular structure, this vision of modality regards all data as useful by labeling it with metadata, description, schema, visualization capabilities and APIs for easy access and analysis on one platform.
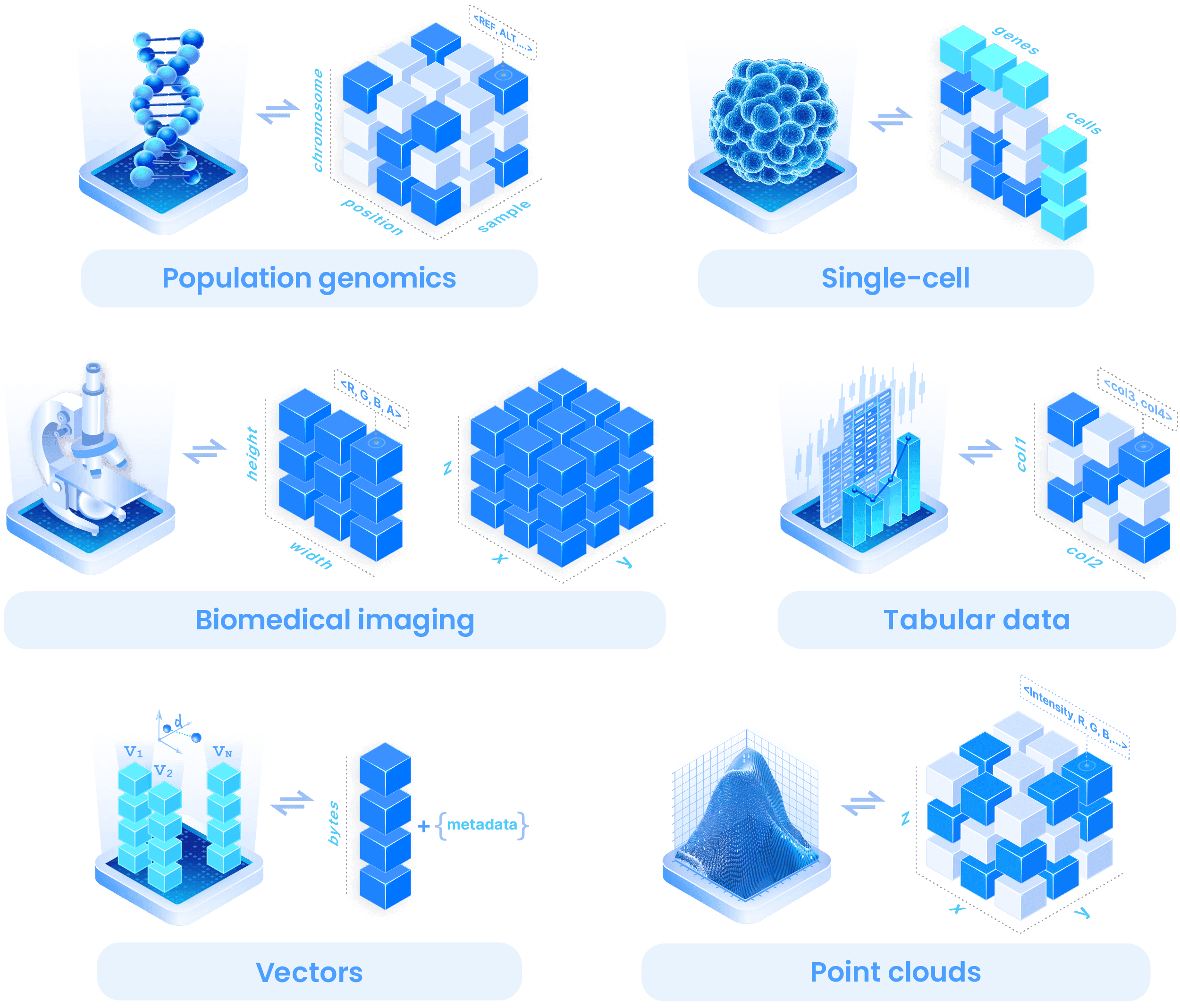
As healthcare and life sciences organizations grapple with the complexities of their diverse data, an omnimodal data management platform is exactly what they need to maximize the value of genomics, single-cell, imaging, clinical data, genomic workflows and other omics data. By following FAIR principles for every modality, this omnimodal platform enables unified authentication, access control and logging while empowering AI agents to easily find and analyze multimodal data at scale.
The result is users can spend less time wrangling and harmonizing complex data and more time building models and agents that embrace the potential of AI for healthcare and life sciences. This unlocks better health outcomes by supporting clinicians with more informed diagnostics and insights into patient health, as well as enabling personalized medicine based on individual patient genetics and drug sensitivity.
TileDB Carrara: The omnimodal intelligence platform for healthcare and life sciences
We built TileDB Carrara to be this kind of omnimodal platform, equipping healthcare and life sciences organizations with omnimodal intelligence to power their lifesaving work. Here’s how Carrara streamlines data management in healthcare:
Everything is a modality: TileDB Carrara treats all data types, including tabular, non-tabular, code, notebooks, APIs and even AI agents, as modalities that contain semantic context through metadata. Carrara's virtual filesystem accommodates all formats, enabling researchers and data scientists to continue using their preferred domain-specific tools.
Masters all data: For high-resolution datasets with performance and scale challenges like single-cell data, Carrara converts this data to TileDB arrays that offer efficient representations optimized for performance and preserving full semantic meaning. This makes it much easier for clinicians and life sciences researchers to query different data types across all their storage for faster and more effective analysis.
Unified authentication, catalog, access control and logging: Carrara brings together healthcare workspaces and teamspaces inside one authentication system. This delivers comprehensive access control and complete activity logging across all modalities to maintain the security and governance required by healthcare and life sciences.
Build AI agents instead of infrastructure: Carrara unlocks the potential of agentic AI by freeing developers from worrying about AI authentication across disparate systems, creating catalog functionality or ensuring efficient access to data. Because Carrara’s omnimodal intelligence handles all this, AI developers in healthcare can focus entirely on designing the agent logic they want and optimizing its performance.
To see how this omnimodal intelligence would work in life sciences, consider the following scenario. A biotech research lead needs to know which genetic variants are associated with treatment resistance in one of her organization’s recent clinical trials. She asks an AI agent to find this information, then explore any correlations between these variants and her team’s imaging biomarkers.
TileDB Carrara can empower this AI agent to authenticate itself once, then access a unified catalog of clinical trial datasets, genomic variants stored as modalities with rich metadata and imaging data stored as modalities with visualization capabilities. As the agent works inside Carrara’s computational framework to analyze this multimodal data, access control is maintained across every data type and all activity is centrally logged for compliance. The agent delivers the exact analysis that the research lead requested—quickly, securely and efficiently.
The future of healthcare and life sciences is omnimodal, unifying all kinds of complex and vital data in one platform designed for discovery. Adding to the transformative power of Carrara, we will soon roll out features like modality builders and AI agent builders. These will enable our customers and partners to push the potential of omnimodal intelligence by creating custom modalities for their unique data types and building specialized agents for domain-specific goals.
For a detailed walkthrough of TileDB Carrara and how it enables healthcare organizations to master different data modalities, watch our full Tech Talk here.
Meet the authors