

Table Of Contents:
What is multimodal AI?
How does multimodal AI work?
What are the key components of multimodal AI?
What are the benefits of multimodal AI?
What are common applications of multimodal AI?
What challenges does multimodal AI face?
What are the differences between unimodal and multimodal AI?
Advantages of multimodal AI over unimodal AI
What is the difference between multimodal AI and generative AI?
How does multimodal AI differ from LLMs?
What is the difference between multimodal AI and agentic AI?
How is multimodal AI used in healthcare?
How TileDB empowers healthcare and life sciences research
Frequently asked questions
Multimodal AI offers benefits like more accurate predictions, faster decision-making, richer context awareness and improved generalization across domains. The most common applications of Multimodal AI include healthcare diagnostics, drug discovery, robotics and autonomous vehicles, fraud detection and natural-language-vision systems. However, multimodal AI also faces challenges around data standardization, computational cost, model interpretability and governance of sensitive information.
Unlike unimodal AI, which learns from one data type, multimodal AI integrates patterns across multiple sources. It differs from generative AI and LLMs by emphasizing understanding and reasoning rather than content creation, and from agentic AI by extending autonomous models with deeper perception and multimodal planning capabilities. In healthcare, multimodal AI brings together genomics, transcriptomics, imaging, clinical data and other complex modalities for precision insights. Let’s begin this end-to-end guide to multimodal AI by defining what multimodal AI is.
What is multimodal AI?
Multimodal AI refers to artificial intelligence and machine learning systems that can understand and reason across multiple types of data, such as text, images, audio, video and sensor signals, by integrating them into a unified model. It is “multimodal” because it processes and relates information from different sensory or data modalities to produce contextually richer outputs. For example, OpenAI’s GPT-4V and Google DeepMind’s Gemini are multimodal AI platforms that can interpret images and text together to answer complex visual-language questions, such as viewing an image of a cake and outputting a possible recipe. This demonstrates how multimodal models connect diverse data sources to achieve human-like comprehension.
How does multimodal AI work?
Here’s an example of how multimodal AI works in healthcare. This approach integrates medical imaging like CT scans with electronic health records (EHRs) and genomic data, then offers clinicians guidance to improve diagnosis and treatment planning for patients dealing with cancer or other serious diseases.
What are the key components of multimodal AI?
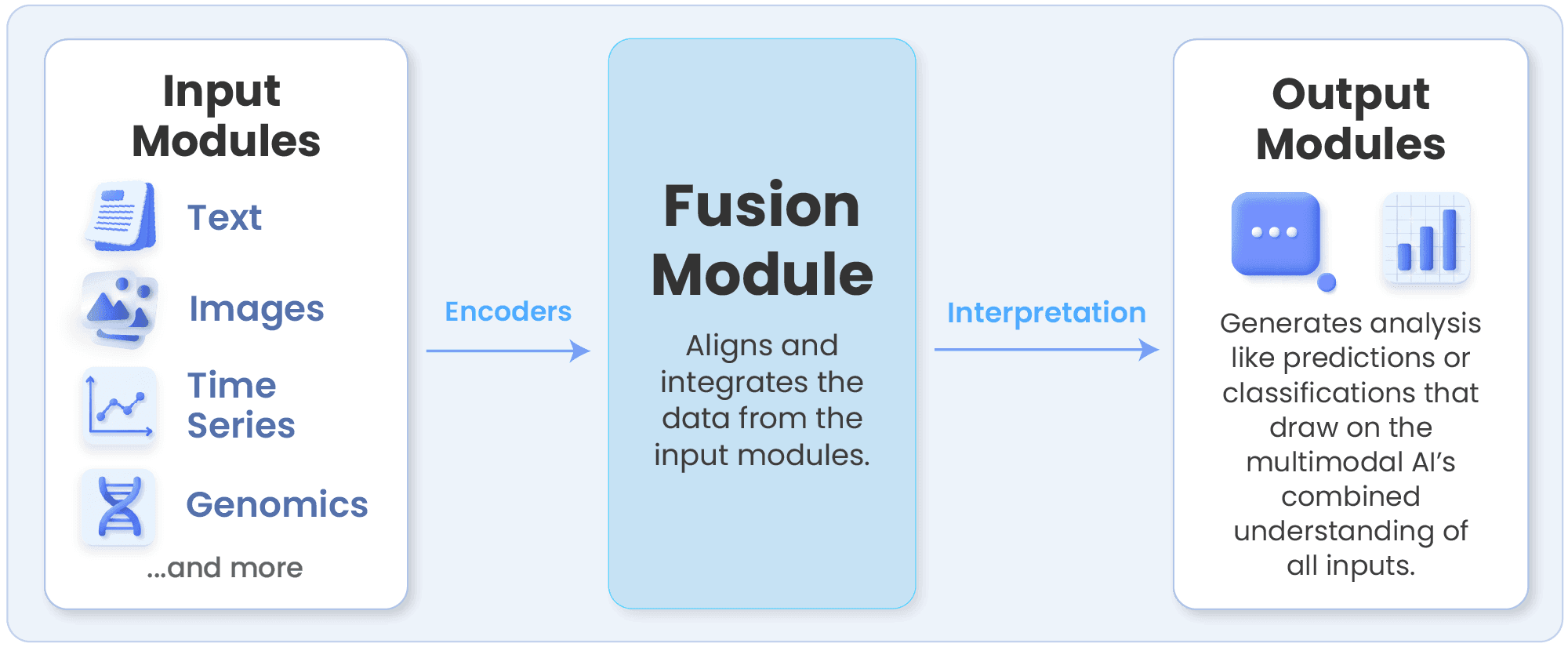
Multimodal AI systems are composed of three primary components that process, align and interpret diverse data types. Each of the following components play a distinct role in ensuring the multimodal AI model can understand and reason across modalities:
Input module: This component first ingests raw data from a range of sources such as medical images, clinical notes, genomic sequences or sensor readings. Next, it converts this data into numerical representations called embeddings. Specialized encoders, like convolutional neural networks for imaging or transformer-based models for text, identify and extract the most informative features from each modality.
Fusion module: The fusion layer combines these modality-specific embeddings into a shared space where the model can find and learn relationships between all the data types. Fusion can occur early (at the feature level), late (at the decision level) or through hybrid methods. In a healthcare setting, fusion enables a multimodal AI model to link radiology findings with lab results and genomic markers to enable more effective diagnostics.
Output module: Once the fused representation is established, the output module interprets everything to generate actionable insights like predictions, classifications or language explanations. Outputs in multimodal AI for healthcare may include disease risk scores or treatment recommendations.
Together, these components allow multimodal AI to connect patterns across a massive range of different data types, producing a more holistic understanding of complex relationships and operational systems.
What are the benefits of multimodal AI?
Multimodal AI is a transformative technology that offers analytic advantages that single-modality AI systems cannot match. Here are some multimodal AI benefits that span research, healthcare and drug development.
Deeper understanding through improved context: By linking varied data like MRI scans, lab results, genomics and clinical notes, multimodal AI creates a more holistic view of patient health. This contextual awareness enables AI models to identify complex correlations like how genetic mutations or environmental factors influence drug responses in select populations.
Richer user experiences: In clinical and research environments, multimodal systems can empower clinicians and scientists by easily processing natural language queries, visual inputs and structured datasets without requiring extensive data harmonization. This enables more intuitive diagnostic tools and decision-support systems that respond seamlessly to how researchers and physicians naturally interact with healthcare data.
Faster research workflows: Multimodal AI automates data alignment and pattern recognition across formats like microscopy images, single cell data assay results, and text inputs like clinician notes and lab reports. This accelerates target discovery and speeds research workflows to find new breakthrough treatments faster.
Improved decision-making and problem solving: Integrating evidence across modalities helps clinicians and data scientists make more informed decisions for diagnoses and treatment. This enables personalized therapies and earlier detection of treatment risks that can lead to better health outcomes.
What are common applications of multimodal AI?
Multimodal AI has strong applications for any industry that has to regularly manage and analyze large and diverse data sources to make everyday and long term decisions. While this applies to a huge variety of verticals, key use cases for multimodal AI include:
Healthcare and life sciences: Multimodal AI integrates imaging, genomic, transcriptomic and clinical data across modalities to improve diagnostics, better predict treatment outcomes, simplify collaboration across teams and accelerate drug discovery. For instance, AI models that analyze radiology scans alongside patient histories can help clinicians detect diseases like cancer earlier and enable precision medicine for more targeted and effective treatment.
Cross-modal search: Systems like Google Multisearch allow users to query with both images and text to enable a more intuitive information retrieval experience. This approach also supports biomedical research by allowing scientists to search literature and images in a single unified context.
Robotics: Robots and autonomous vehicles equipped with multimodal perception combine vision, sound and tactile feedback to navigate complex environments in varying weather conditions while interacting safely with humans. This has all kinds of transformative applications, from manufacturing to transportation to surgery.
Customer service: Multimodal chatbots can interpret users’ speech, facial expressions, and text to provide more human-like and empathetic interactions while saving human agents for the most complex cases.
Creative content generation: Models such as OpenAI’s Sora and Runway Gen-2 are capable of merging text, video and audio inputs to generate realistic video and animated content for design mockups, entertainment, training and other communication purposes.
Education: Adaptive learning platforms can draw multimodal data from students’ speech, writing and visual cues to personalize instruction and assess engagement in real time. MIT used multimodal AI to create Interactive Sketchpad, an AI-powered tutoring platform that assists students in solving math problems through interactive, visual collaboration with virtual instructors.
What challenges does multimodal AI face?
While multimodal AI delivers powerful insights, it also faces challenges in data management, computation costs, governance and more. Key issues of this rapidly evolving field include:
Data curation and standardization: Combining text, images, sensor signals and other diverse data sources requires careful alignment to avoid missing vital information. In healthcare, inconsistent metadata and incompatible file formats across imaging systems and EHRs can hinder AI training and reproducibility. Without robust curation pipelines that include coaching and labeling from human experts, multimodal models risk learning from incomplete or mislabeled data. This can cause AI to make mistakes, which in healthcare can have especially dangerous consequences.
Computational cost and infrastructure: Unimodal AI needs significant computing power to function, and multimodal AI scales this need further. Training and deploying multimodal models demand immense processing power, memory and storage. Large-scale fusion models such as vision-language transformers are even more demanding, requiring distributed infrastructure and optimized data access patterns to function, especially for institutions managing petabyte-scale research data.
Bias and data imbalance: When one modality dominates (for example, English-language text or specific imaging equipment types), the model can rely too much on that modality. This creates inherent bias that produces skewed or inequitable results. For example, a Cedars-Sinai-led study found that LLMs including Claude and ChatGPT generated less effective treatment recommendations when a patient’s race was implied or explicitly stated as African-American.
Explainability and interpretability: As multimodal systems integrate multiple data sources, tracing which inputs most drive a prediction becomes increasingly difficult. In clinical AI, this complexity makes it difficult to validate research results for regulatory approval. In addition, healthcare providers must justify care decisions and clinicians are reluctant to rely on recommendations from AI platforms that lack explainability.
What are the differences between unimodal and multimodal AI?
The main difference between unimodal and multimodal AI is the variety and integration of data each can process. Unimodal AI focuses on learning from a single data type such as text, audio or images, while multimodal AI integrates and analyzes multiple data sources to capture deeper relationships and context. This enables multimodal systems to make more comprehensive and accurate inferences, especially in complex, data-rich environments like healthcare or autonomous systems. Here are the main differences between the two:
Dimension | Unimodal AI | Multimodal AI |
Input data | Trained on one data modality, such as text-only or image-only datasets. | Integrates diverse modalities like text, images, video, audio, genomic or sensor data into unified models. |
Contextual understanding | Limited to the scope of one data source, which reduces insight across domains. | Learns correlations across data types, creating richer analytic context and deeper understanding. |
Complexity & infrastructure | Easier to train and deploy, and requires less data processing and compute power. | Demands high-performance storage, alignment algorithms and large-scale compute resources. |
Use cases | Language translation, object recognition, speech-to-text systems and grammar/editorial assistants. | Disease diagnosis, cross-modal search, autonomous systems and financial market analysis. |
In short, unimodal AI works best at specialized single-input tasks, while multimodal AI connects diverse data streams to deliver more holistic analysis and decision-making across domains.
Advantages of multimodal AI over unimodal AI
Multimodal AI offers several advantages that make it more powerful and versatile than traditional unimodal systems, including:
Higher accuracy: By integrating many different data sources, multimodal AI improves predictive performance and reduces uncertainty in its analysis. For example, pairing medical imaging with lab data can produce more reliable diagnostic outcomes than either source alone.
Greater context awareness: Multimodal systems are capable of understanding relationships across modalities, enabling deeper reasoning and more useful analysis. In drug discovery, linking chemical structure data with genomics and clinical outcomes enables models to better identify targets that lead to promising treatments.
Richer user experiences: Integrating visual, auditory and textual inputs allows more natural interactions between AI and users. Voice assistants and diagnostic tools become more intuitive when they can interpret speech, tone, gestures, facial expressions and contextual cues together.
Improved generalization: Models trained on diverse data types are more resilient against noise and variation, making them better suited for dynamic real-world environments such as healthcare and research collaboration.
What is the difference between multimodal AI and generative AI?
While multimodal AI and generative AI often overlap, their primary goals differ. Multimodal AI focuses on understanding and reasoning across multiple data types, whereas generative AI is designed to create new content like text, images or audio based on learned patterns. Put simply, multimodal AI connects information while generative AI produces it. Here are the most important differences between multimodal and generative AI:
Multimodal AI | Generative AI | |
Core purpose | Integrates and interprets data from multiple modalities for deep analysis and context-aware prediction. | Generates new data, code or content that mimics or extends existing examples. |
Input | Multiple existing data types such as text, video, images, genomic data sensor signals and more. | A user prompt, seed dataset or learned distribution to generate new outputs. |
Output | Analytical insights, classifications, predictions or cross-modal retrievals. | Synthetic text, images, videos, audio, code or simulated datasets. |
Key techniques | Feature fusion, cross-attention, embedding alignment and joint representation learning. | Diffusion models, GANs, transformer-based decoders and reinforcement learning from human feedback. |
In practice, these approaches increasingly intersect. Generative models like GPT-4V or Sora rely on multimodal inputs to produce useful cross-media outputs. This suggests the future of multimodal AI will be inseparable from the future of generative AI as each rely on the other’s capabilities in unified AI platforms.
How does multimodal AI differ from LLMs?
Dimension | LLMs | Multimodal AI |
Scope of data | Processes and learns exclusively from textual input like books, research articles, web content and code. | Integrates multiple modalities including text, images, audio, video, genomics, and geospatial data. |
Core function | Understands, summarizes and generates human language content. | Aligns and reasons across different data types to provide cross-modal insights and predictions. |
Architecture | Transformer-based language encoder-decoder optimized for sequential text understanding. | Multi-encoder or hybrid transformer architecture designed to process and integrate heterogeneous data embeddings. |
Primary output | Text-based responses such as article summaries, answers to questions or code completions. | Visual or predictive analysis derived from multiple data sources. |
Put simply, LLMs are specialists in language-based reasoning, while multimodal AI generalizes its reasoning across all kinds of data modalities to expand language understanding into more complex analysis and predictions.
What is the difference between multimodal AI and agentic AI?
While multimodal AI and agentic AI are often complementary, they address different layers of intelligence. Multimodal AI focuses on understanding by integrating and interpreting diverse data types to form a unified representation of the world. In contrast, Agentic AI focuses on independent action, relying on reasoning, planning, and feedback loops to autonomously pursue goals and adapt to dynamic environments. Here are key differences between multimodal and agentic AI:
Dimension | Multimodal AI | Agentic AI |
Core purpose | Integrates and interprets multiple data modalities for contextual understanding and prediction. | Plans and executes tasks autonomously based on goals, real-time feedback, and environmental inputs. |
Input focus | Text, images, video, audio and complex datasets like single cell data and transcriptomics. | Goals, prompts, contextual cues and multimodal data streams. |
Output | Analytical insights, classifications or complex predictions. | Actions, decisions or adaptive workflows in pursuit of specific objectives. |
Architecture | Multi-encoder transformer or fusion-based models for data comprehension. | Agent frameworks that combine perception, reasoning, planning and memory modules. |
Dependency | Often a component of larger AI systems; requires data to be made FAIR in order to use it. | May incorporate multimodal AI as part of its perception module. |
Key applications | Healthcare analytics, scientific discovery and multimodal search. | Workflow automation, research assistants, customer support bots and autonomous systems. |
In essence, multimodal AI gives machines deeper understanding while agentic AI gives them autonomous purpose. The integration of multimodal ai in autonomous systems is also key, as it allows intelligent agents to act on multimodal understanding to achieve changing objectives for better outcomes.
How is multimodal AI used in healthcare?
Multimodal AI has different uses in the healthcare industry, from precision diagnostics to genomic medicine. Some key uses of multimodal AI in the healthcare industry and medical applications are listed below:
Precision diagnostics: Models that integrate radiology images with EHR data, lab results and genetic profiles can detect conditions like lung cancer or heart disease earlier and with greater accuracy to improve outcomes for patients.
Genomic medicine: Multimodal systems can link genomic variant data with clinical data and patient histories to help clinicians identify biomarkers of rare disease, predict therapy response in oncology and design personalized therapies based on a patient’s genetic profile.
Clinical decision support: AI that interprets speech and video from patient encounters alongside medical notes and EMRs can assist clinicians in documenting visits and spotting early warning signs of health complications.
Target discovery: Different labs and vendors use different modalities for life sciences research, making it complex to harmonize this data for effective analysis. Multimodal AI can rapidly analyze varied data types across research teams to better identify genomic targets of interest, as long as those datasets are made FAIR and readable to AI.
How TileDB empowers healthcare and life sciences research
TileDB provides a database designed for discovery that helps healthcare organizations and research hospitals manage and analyze multimodal data efficiently and securely. By unifying complex modalities like imaging, genomics, single cell data and EHRs into a single, queryable format, TileDB enables teams to perform advanced analysis without costly data movement or duplication. Its multi-dimensional array-based architecture optimizes both storage and compute performance, helping institutions reduce infrastructure costs while accelerating model training and simulation workflows. TileDB Carrara will take these capabilities further by introducing omnimodal data intelligence that can effectively govern, structure and analyze all of an organization’s data types in one platform.
For target discovery and precision medicine, TileDB empowers researchers with a trusted research environment (TRE) to correlate imaging biomarkers, genomic profiles and other complex datasets at scale. Built-in access control and versioning features also ensure compliance with privacy regulations and FAIR data principles while enabling seamless collaboration among bioinformaticians, data scientists and clinicians. By turning siloed datasets into a unified research foundation, TileDB makes it easier for healthcare organizations to unlock actionable insights from their multimodal data and drive scientific breakthroughs. To learn more about how TileDB can unlock the potential of your multimodal data, contact us.
Frequently asked questions
Is ChatGPT a multimodal AI?
Yes. ChatGPT is a multimodal AI that can process both text and images, enabling it to interpret visuals and respond contextually. While earlier versions like GPT-3 and GPT-4 were text-only, newer versions like GPT-4V (Vision) and GPT-5 extend ChatGPT’s capabilities across text, image and document modalities.
How does multimodal AI impact user experience?
Multimodal AI enhances user experience by allowing AI systems to understand and respond through multiple input types like text, voice, gestures and images. This leads to more intuitive, and adaptive interactions, enabling tools like virtual assistants to feel more human-centered and context-aware.
What tools are available for building multimodal AI?
Key platforms include Hugging Face Transformers (open source, pretrained multimodal models), OpenAI GPT-4V (proprietary, text-image understanding), Google DeepMind Gemini (proprietary, cross-modal reasoning), Meta’s LLaVA (open source, vision-language training) and TileDB (unifies and manages multimodal data at scale).
How can you evaluate multimodal AI performance?
Evaluation uses all kinds of benchmarks, including VQA v2 (visual question answering) and MedMNIST (biomedical image classification). Metrics include accuracy, F1-score, BLEU and human-alignment ratings, which are often supplemented with domain-specific tests for clinical or scientific relevance.
What are the leading trends in multimodal AI?
Key trends include developing smaller, more efficient models that reduce compute demands, real-time multimodal inference for interactive use, edge deployment in medical or industrial devices and advanced fusion techniques that improve alignment across modalities for better accuracy and interpretability.
Meet the authors