


One of the strongest capabilities of TileDB is that it is a cloud-native database, i.e., particularly optimized for cloud object stores (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage, MinIO and any other S3-compliant object store). In addition, TileDB is cool in that the user experience of accessing an array on my local machine is the same as accessing a remote TileDB array on cloud object storage. In this short article, I will show you the very basics of working with TileDB arrays on cloud object stores, and how easy it is to transition from your laptop to cloud storage.
Local setup
Later in this guide, I will use Amazon S3 for the object storage component. So if you don't already have an AWS account, you'll want to investigate that before reading further. You'll also want to install and configure the AWS CLI. In the end of the article I will also explain how to use other cloud object stores as well; the user experience is almost identical.
I will use the Python API of the TileDB Embedded storage engine (conda install -c conda-forge tiledb-py). Below I import the necessary libraries and create a very simple 1D array. Note that the descriptions in this article apply to any TileDB array, but you can check my recent 101 blogs on Arrays and Dataframes for some more information on creating various types of arrays.
import tiledb
import numpy as np
import os, shutil
# Local path
array_local = os.path.expanduser("~/my_array")
# Create a simple 1D array
tiledb.from_numpy(array_local, np.array([1.0, 2.0, 3.0]))
# Read the array
with tiledb.open(array_local) as A:
display(A[:])
array([1., 2., 3.])
Let’s take a look at how our array looks like locally on my laptop:
!tree ~/my_array
/Users/mikebroberg/my_array
├── __commits
│ └── __1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18.wrt
├── __fragment_meta
├── __fragments
│ └── __1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18
│ ├── __fragment_metadata.tdb
│ └── a0.tdb
├── __labels
├── __meta
└── __schema
└── __1684778158689_1684778158689_a2affd4b9f7245b4a69826fe53626d57
8 directories, 4 files
My array is just a folder containing files and other subfolders. Next, I describe how to store TileDB arrays on S3 and directly access them.
Moving an existing TileDB array to S3
The only thing you need to do in order to move a TileDB array from your laptop to S3 is to just upload the entire array directory with all its contents. You can do this either from the AWS web console, or via the AWS CLI.
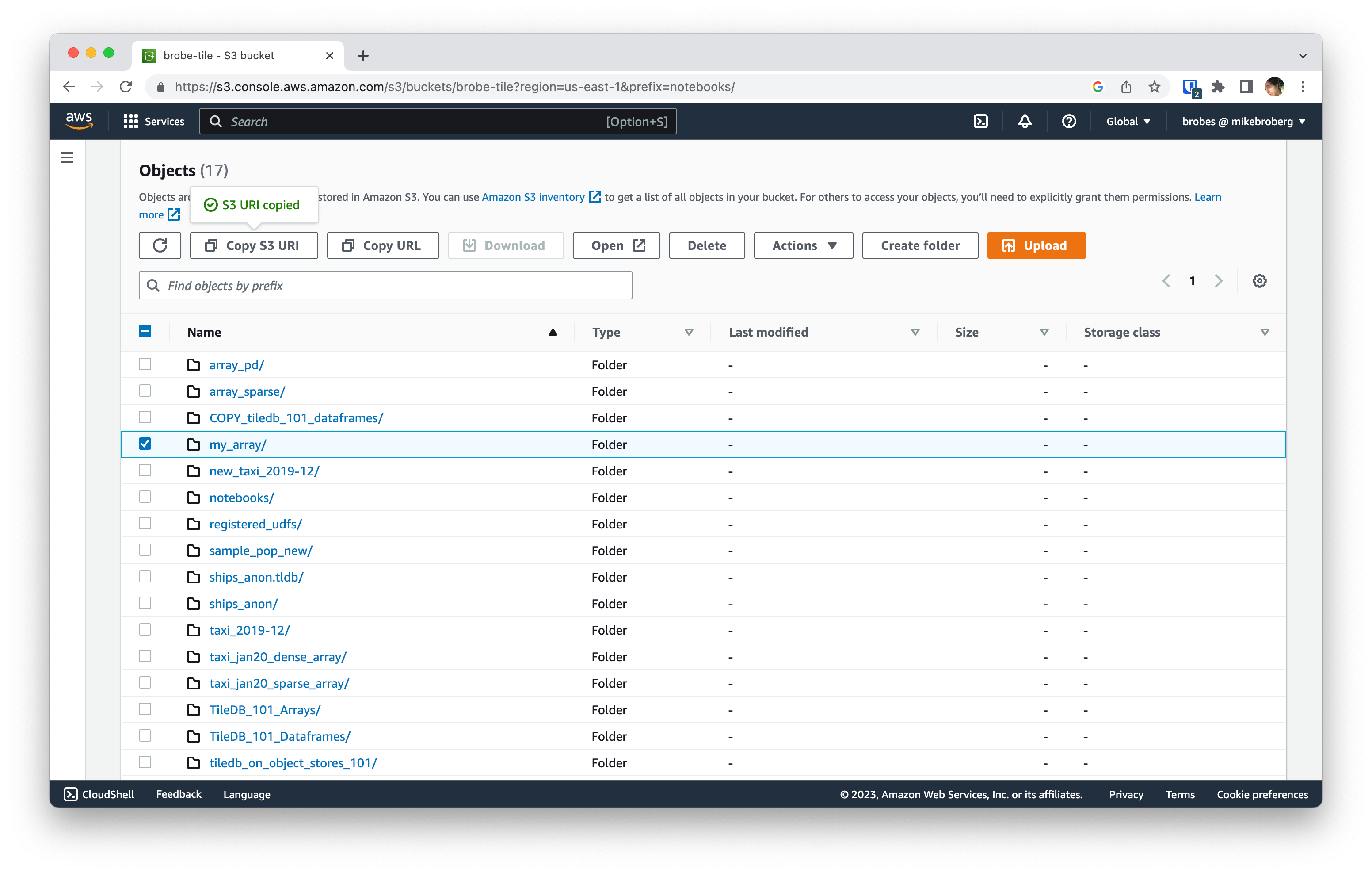
In the AWS web console, choose your bucket, hit the orange Upload button, and then choose Add folder.

Close the upload screen, then select the object you just uploaded and click the Copy S3 URI button.
If you choose to use the AWS CLI (and assuming that you have set up your AWS credentials so that you can access the S3 bucket of interest from your laptop), you can issue a command like the following to move your TileDB array to object storage:
aws s3 sync my_array s3://brobe-tile/notebooks/my_array
upload: my_array/__commits/__1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18.wrt to s3://brobe-tile/notebooks/my_array/__commits/__1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18.wrt
upload: my_array/__schema/__1684778158689_1684778158689_a2affd4b9f7245b4a69826fe53626d57 to s3://brobe-tile/notebooks/my_array/__schema/__1684778158689_1684778158689_a2affd4b9f7245b4a69826fe53626d57
upload: my_array/__fragments/__1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18/a0.tdb to s3://brobe-tile/notebooks/my_array/__fragments/__1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18/a0.tdb
upload: my_array/__fragments/__1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18/__fragment_metadata.tdb to s3://brobe-tile/notebooks/my_array/__fragments/__1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18/__fragment_metadata.tdb
(base) mikebroberg@MIKEs-MBP ~ %
You can see that the TileDB array was cloned to S3 by listing its contents with the CLI:
aws s3 ls s3://brobe-tile/notebooks/my_array --recursive
2023-05-22 14:26:07 0 notebooks/my_array/__commits/__1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18.wrt
2023-05-22 14:26:07 3109 notebooks/my_array/__fragments/__1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18/__fragment_metadata.tdb
2023-05-22 14:26:07 44 notebooks/my_array/__fragments/__1684778158707_1684778158707_d8d4313ac69245bdb43d684d9065514a_18/a0.tdb
2023-05-22 14:26:07 167 notebooks/my_array/__schema/__1684778158689_1684778158689_a2affd4b9f7245b4a69826fe53626d57
(base) mikebroberg@MIKEs-MBP ~ %
Query TileDB arrays directly from S3
I can slice any portion of my remote arrays on S3 with minimal changes to my code, and without having to download the entire array locally. TileDB is cloud-native and serverless, which means that each TileDB array on S3 has all the appropriate information stored in a self-contained way in its folder, which allows the (serverless) TileDB Embedded library to efficiently access it directly from S3. I simply need to provide the S3 URI and pass an additional configuration object with my AWS credentials.
# The S3 URI path of my array
array_s3 = "s3://brobe-tile/notebooks/my_array/"
# My AWS keys
aws_key = "<your_aws_access_key_id_here>"
aws_secret = "<your_aws_secret_access_key_here>"
# or, in a Jupyter notebook:
#aws_key = !aws configure get aws_access_key_id
#aws_secret = !aws configure get aws_secret_access_key
# The configuration object with my AWS keys
config = tiledb.Config()
config["vfs.s3.aws_access_key_id"] = aws_key #aws_key[0] via AWS CLI
config["vfs.s3.aws_secret_access_key"] = aws_secret #aws_secret[0] via AWS CLI
config["vfs.s3.region"] = "us-east-1"
with tiledb.open(array_s3, mode='r', ctx=tiledb.Ctx(config)) as A:
display(A[0:1])
array([1.])
Creating a TileDB array directly on S3
You can of course create a TileDB array directly on S3, without having to first create it locally and upload it in a separate step later.
# The only changes from before are:
# 1. Pass the S3 URI instead of the local one
# 2. Pass the config with the AWS keys I created above
tiledb.from_numpy(array_s3, np.array([1.0, 2.0, 3.0]), ctx=tiledb.Ctx(config))
# I can read the array simply as
with tiledb.open(array_s3, mode='r', ctx=tiledb.Ctx(config)) as A:
display(A[:])
array([1., 2., 3.])
Working with other cloud object stores
As a cloud-native database, TileDB also supports other popular object stores, such as Azure Blob Storage and Google Cloud Storage. The only changes you need to make to the above code are as follows:
- Use the appropriate URI that points to the desired array on cloud object storage
- Add the appropriate keys to the TileDB configuration object
Azure
TileDB offers native Azure blob storage access. Support is offered for both account keys and SAS tokens.
# The configuration object with my Azure keys
config = tiledb.Config()
config["vfs.azure.storage_account_name"] = "your_account_name"
config["vfs.azure.storage_account_key"] = "your_account_key"
with tiledb.open("azure://my-bucket/my-array", mode='r', ctx=tiledb.Ctx(config)) as A:
display(A[0:1])
Google Cloud Storage
Google cloud storage can be configured for access directly or via the S3 compatibility API.
Google Cloud SDK requires first defining a credential file and setting an environmental variable, if this credential file is not located in the default location in your home directory.
GOOGLE_APPLICATION_CREDENTIALS=/path/to/gcs-creds.json
Now you can access google cloud storage buckets by setting the project_id configuration parameter.
# The configuration object for Google Cloud
config = tiledb.Config()
config["vfs.gcs.project_id"] = "my_project_id"
with tiledb.open("gcs://my-storage/my-array", mode='r', ctx=tiledb.Ctx(config)) as A:
display(A[0:1])
Other Storage Backends
TileDB supports any S3-compatible object store, including but not limited to Wasabi, Cloudflare R2, MinIO and more.
Onward!
In this article I describe the most basic functionality of TileDB’s object storage support. All the above code can be run with the open-source TileDB Embedded library and its entire open-source ecosystem (across life sciences, geospatial, ML & data science, and distributed compute technologies). The complete example notebook that accompanies this article is available to download from or launch directly on TileDB Cloud. We'll discuss TileDB Cloud more in future articles, but look for other content here soon on updates, versioning and schema evolution for TileDB arrays. Stay tuned!

Mike Broberg
Technical Marketing Manager
Continue Reading

Apr 10, 2025
The Future Of Life Sciences Cannot Be Achieved Without A New Approach To Frontier Data
If you were searching for a famous treasure, would you rather look in the same locations others had already tried, or tr...

5 min read

Mar 26, 2025
Why Life Sciences Organizations Need A Database Designed For Discovery
Solve tough data challenges with more flexible technology
Discovery. It’s more than a clever word chosen by a marketing ...

6 min read
Stay connected
Get product and feature updates.
Loading form...
Your personal data will be processed in accordance with TileDB's Privacy Policy.By subscribing you agree with TileDB, Inc. Terms of use. Your personal data will be processed in accordance with TileDB's Privacy Policy.